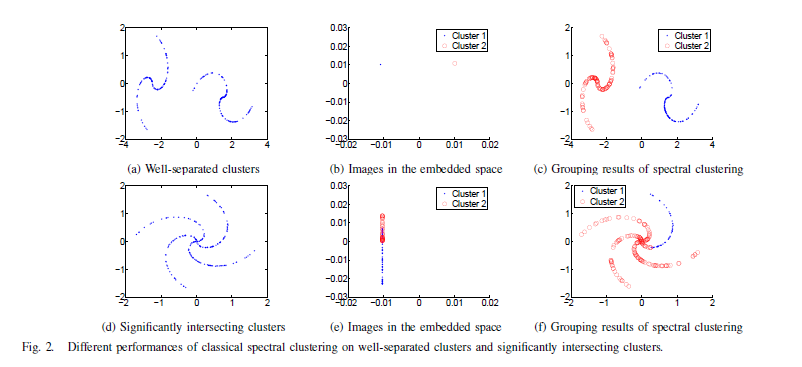
上图中,a、b、c来自于良好分离的两个类的数据聚类结果演示,d、e、f来自有明显相交的数据聚类演示。从图a的数据可视化结果,我们能轻易的了解到两个”S”型的数据簇良好分离,可以被轻易的分割为两个类。通过仔细调整最近邻参数K或者数值参数![]() 轻易获得邻接矩阵W的特征。最理想的情况就是来自不同簇的点之间的权重为w=0;这时,谱方法就会将同一个簇内的点映射到空间的一个独立的点,依次类推,在这样的一个k维空间中就存在k个互相正交的点(如图b所示)。最后将这些点返回映射到原始数据中,聚类结果就如图c所示。
轻易获得邻接矩阵W的特征。最理想的情况就是来自不同簇的点之间的权重为w=0;这时,谱方法就会将同一个簇内的点映射到空间的一个独立的点,依次类推,在这样的一个k维空间中就存在k个互相正交的点(如图b所示)。最后将这些点返回映射到原始数据中,聚类结果就如图c所示。
然而,当遇到图d所示的数据时,我们可以看到上图d中的数据之间存在明显的相交处,此时邻接矩阵将会因为成对点之间的不靠谱的相似度而不能很好的反映数据之间的关系。比如说,一般情况下,不同簇内的点之间的相似度很低(接近0)但是在上图中数据的交汇处的点之间的相似度将会因为它们的欧式距离很小变得很高。简而言之,我们试图将上图d中的数据聚为两类,但是因为这两个类彼此之间关系相当紧密导致无法将其分为两个子集。
特别注明:部分图片和内容源于相关论文或书籍,如涉及侵权,请联系删除。