由于本文的研究目标为课堂行为识别,且目标场景是大视角下的教室场景,所以会有多个行为目标出现,这要求了网络算法本身具有空间分辨能力。而大部分基于图片的行为识别网路应用对象是小视角下的行为场景,往往场景下只有一个行为,并不涉及空间分辨问题,所以考虑到空间分辨能力,必须对网络构架进行相应调整。同时考虑到本文目标在于特定的三种课堂行为进行识别,目标对象小于大多数网络问题,所以可以采用深度网络模型和传统手工特征设计方法相结合构建整体算法设计。
本文目标对象主要是玩手机、睡觉和交流三种行为的识别,下文分别介绍三种行为对应的识别流程
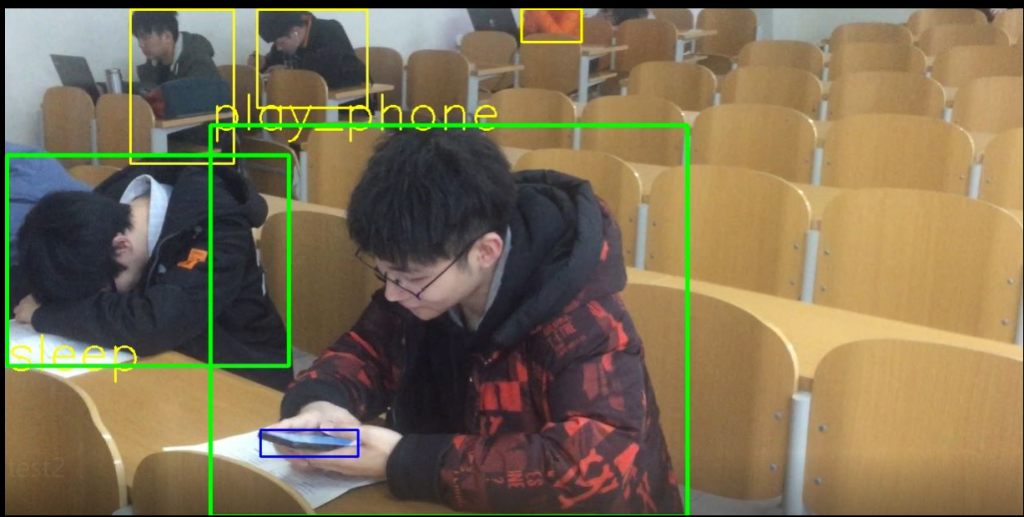
鉴于“课堂玩手机”行为的语义理解,本文这里采取只要在视野明显区域出现手机对象,即认为存在玩手机的行为,玩手机的对象则利用边界框回归方法确定。具体流程为首先通过深度网络方法对图像内的手机对象和学生对象进行检测识别,并确定每个对象的边界框位置;然后判断是否存在手机对象,如果不存在手机对象则停止流程,如果存在手机对象则寻找与该手机对象边界框重叠面积最大的学生边界框,并判断该学生有玩手机行为。
鉴于“课堂睡觉”行为的语义理解,本文这里采取只要学生对象无法检测到面部对象,则认为该学生存在睡觉行为。具体流程为首先通过深度网络方法对图像内的学生对象进行检测,并确定其边界框位置,然后对于每个学生对象边界框区域内进行面部对象检测,如果检测到面部对象则认为该学生在听课,若没有检测到面部对象则认为该学生在睡觉。考虑到整体模型的复杂性,此处的面部对象检测不采用深度网络方法,而是采用传统的机器学习方法,利用haar特征进行面部对象检测。
鉴于“上课交流”行为的语义理解,由于交流是明显具有语义的行为(需要有言语信息,但图片无法反应言语传递),出于可行性考虑,本文这里采取只要学生对象出现大面积交叉遮挡现象则认为学生存在交流行为。具体流程为首先通过深度网络方法对图像内的学生对象进行检测,并确定其边界框位置,然后判断每对边界框的重叠面积,如果出先重叠面积超过设定阈值的情况(本文设定阈值为两个边界框面积之和的30%)则认为这对边界框的两个学生对象有交流行为。对于判断为交流的两个学生对象,则将其边界框看作是同一个边界框,继续加入与其他学生对象的边界框的判断,以此检测多人交流的行为,最终可以判断出所有有交流行为的学生对象。